Blocking Compromised Passwords on PyPI
Approximately a month ago there was an
incident
on npm where an attacker was able to compromise the account of one of the ESLint
maintainers and publish malicious releases of projects that user had access to. These
malicious releases attempted to then steal the accounts of other user’s by stealing
their ~/.npmrc which contained the account credentials that can be used to upload
packages for other projects.
While this particular incident occurred to eslint and took place on npm, it would be a mistake to think that the same couldn’t be true on PyPI itself.
With that in mind, I set out to try and add mitigations to PyPI. There are a lot of mitigations that are employed for this case ranging from education, to password rotation, and two factor authentication (2FA). Password rotation has been shown1 to actually decrease the quality of passwords that user’s are likely to make, which leaves education and 2FA authentication.
Unfortunately they both suffer from one critical flaw: It’s not reasonable to mandate either across the entire PyPI user base2. In addition to that, education in particular has a particularly poor response rate outside of a 1:1 sitting.
Taking a step back, the root cause of the issue is that a user may use the same password in two different places, and one of those places can suffer a breach that leaks their passwords3 and they eventually end up out in the public. Once in the public it doesn’t matter how securely generated the password was, it will get included in dictionaries for use in automated Credential Stuffing attacks or targeted attackers will locate it, typically alongside identifying information like an email address, and they’ll then go and manually try it out on any site where that person has an account hoping to find a reused password. Prior to the original breach, the reused password was perfectly functional at protecting the account.
So if the problem ultimately comes from a password appearing in a breach, why not just take the same breaches that the attackers are using, and use them not to attack our users, but to keep them secure?
The first problem to implementing this, is getting the data to begin with. The breaches are made by different groups of people over the years, and are sometimes rolled up into collections of passwords that are then passed on along. It would be a non-trivial amount of effort to scour the internet and locate all of these breaches and collate them into a master list of compromised passwords.
Fortunately, Have I Been Pwned has already done the hard work for us here, and has collated all of the public breaches that it can find, and through their “Pwned Passwords” API, allow us to securely query4 517 million passwords that have appeared in breaches.
PyPI securely stores all user passwords using either bcrypt or argon2, depending on when the last time the user authenticated to the site, which means that we could not iterate over the entire list of users and check their passwords. However, users do have to submit their plaintext password whenever they are actively logging into the site or uploading a file, which gave us the perfect time to take that password and check it against the HIBP data.
After we had a means for checking if a password was compromised, we needed to get some sense of how many affected accounts there was, as that would ultimately play a large factor in how we approached enforcement. We added the HIBP checking code to the PyPI code base, but we didn’t do anything with the result except increment a metric that we sent to PyPI’s DataDog account.
Taking a look at the data for the first day, we saw a total of 714 authentications5 out of a total of 10.1k used a password that was compromised and listed in the HIBP data. Visualized this looked like:
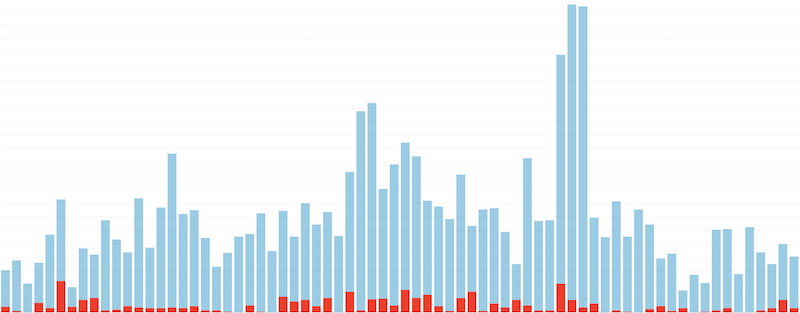
This confirmed that the exact same thing that had happened on npm was currently possible on PyPI and that the numbers of users was high enough to be concerning, but not so high that we couldn’t afford to be forceful in our approach.
When deciding on what enforcement looked like our primary goal was to get the user onto a strong, uncompromised password, but the fact that we knew for a fact that this user’s password was compromised meant that we couldn’t be sure if the person currently authenticating was the expected user, or an attacker that had found their credentials and were attempting to attack that user.
Ultimately we decided since checking the password against HIBP was only possible while the user was attempting to authenticate, we could interupt their flow and even though they had a valid password, fail the authentication with an error. At the same time we would disable the user’s password as a fail safe against this password ever being usable again, and finally we send an email to the user detailing what has just occurred to their account. This would result in the user no longer having a password, forcing them to reset their password before they would be able to log back into their account again.
This means that once a password appears in a public breach that is known to HIBP it is effectively disabled on PyPI regardless of whether it is a current user’s password or not. Additionally by forcing the user to reset their password to regain access to their account, rather than just forcing them to change their password, we raise the bar for an attacker to require them to also control the user’s email address.
That has been live for about 36 hours, and in that time over 120 users have attempted to authenticate with a compromised password. Those 120+ users are maintainers on a combined 400 projects, which in total had 2.9 million downloads in the past 30 days. The top 5 in terms of downloads had 687k, 567k, 555k, 345k, and 87k respectively. To give a little bit of perspective, in that same time frame, if you look at all of the users who performed some action on a project, and then expand that out to include all of the projects those users have access to, we can see that there were 12k total possible affected projects6, or roughly 3%. The total number of authentications with a compromised passwords that have been made in the last 24 hours are now at 66, down from 714 in a single day prior.
While it’s still relatively early to pass a final judgement, so far using HIBP to “burn” every leaked password seems to be a successful and effective mitigation for reused and leaked passwords. By checking at authentication time, the moment a password appears in the HIBP corpus of breached passwords, we effectively invalidate every password that has appeared on another site and had been leaked. Given that this policy can be applied globally across all users it provides greater coverage than any of the opt-in solutions do.
-
You can read more in depth from one of the original papers on the subject: The Security of Modern Password Expiration: An Algorithmic Framework and Empirical Analysis. The general gist of which is that user’s basically just used the same password over and over again with some slight tweaks to it (e.g. hunter2 -> hunter3) that would be trivial for a computer attempting to guess a password to derive as well. ↩︎
-
Before someone freaks out, I am not saying that 2FA is a bad idea, and PyPI will implement 2FA as well. However there are larger ecosystem changes that need to happen before that can be done since the upload API does not currently have a way to prompt for a 2FA token, and none of the tools to upload have 2FA built into them.
Additionally, 2FA solves a somewhat different problem. If someone has the password “123456” (the most popular password in the HIBP data) and 2FA auth, what they effectively have is single factor auth, except instead of a password being the single factor, the 2FA token they use is that single factor. Thus this works in concert with 2FA to ensure that there are truly two factors. ↩︎
-
Ideally all of these passwords in these breaches would be hashed with a strong hash like pbkdf2, bcrypt, scrypt, or argon2. Unfortunately there are a lot of sites out there that use plaintext or a general purpose hashing function. ↩︎
-
Obviously one problem with this kind of service is that in order to query to see if a particular password has ever appeared in a breach, you would have to either submit the password to the service, or iterate over all of the passwords. Neither of which are really an approachable solution to the problem. HIBP has come up with a pretty neat way of working around this problem, which effectively combines both approaches to make one that actually is workable without leaking (much) data to the service itself.
Basically you take a given password, and get the hex encoded sha1 digest of it. Then you take the first 5 characters of that digest and submit that to the HIBP service, which will return a list of all of the sha1 hashes of passwords that start with those same 5 characters. Locally you can then iterate over the returned hashes and do a simple comparison to determine if the given password exists in the dataset or not.
This scheme means that the most that HIBP ever learns, is the first 5 characters of the sha1 digest of the password, which is not enough to recover any information about the password, and since the actual comparison is done locally, HIBP does not even know if the given password was in their data or not. ↩︎
-
It’s important to note that these are authentications, not users. If someone makes a release that includes 5 files, they’ll make 5 HTTP requests, and each HTTP request will be a distinct authentication. However signing into the Web UI would be a single authentication for the act of signing in, but further requests using that same session would not be counted as additional authentications. ↩︎
-
Unfortunately we don’t have an audit log of user authentications, only one that shows when they’ve made some action that modified the state of a project. So this number is a little bit on the low side, but most authentications that happen to PyPI are via the upload API, which would get logged in the audit log. ↩︎